How to scrape table data ?
This article is going to show you definite guide to scrape table data from websites using Python. So, for getting started you need to have python installed obviously and also you need to have a couple of packages namelyBeautifulSoup and Pandas.
BeautifulSoup is a popular library for web scraping and parsing HTML or XML documents. Pandas is a popular data manipulation and analysis library used in Python.
you can install both of these packages using pip install command pip install bs4 and pip install pandas should do the trick. If these runs into any problem you would have to refer the internet on how to go about installing them.
Also if you need you can go ahead and install jupyter notebook since we are working with pandas it provides an ease of visualising the data not a necessity purely optional, you can code along with a code editor like Vscode or any other.
So first we need to import BeautifulSoup from bs4 module and I forgot if you don’t already have requests installed you can do pip install requests
from bs4 import BeautifulSoup
import requests
Now, for this example I will be using the pokemon database as the table I will be scraping you can view it here.
page = requests.get('https://pokemondb.net/pokedex/all')
soup = BeautifulSoup(page.text,'html')
Next we are making a get request to the page where the table containing the data is and after that we are parsing the html content of the page into a BeautifulSoup object which we can manipulate later.
The next part we have to go to the page where the table is and you need to right click and inspect element
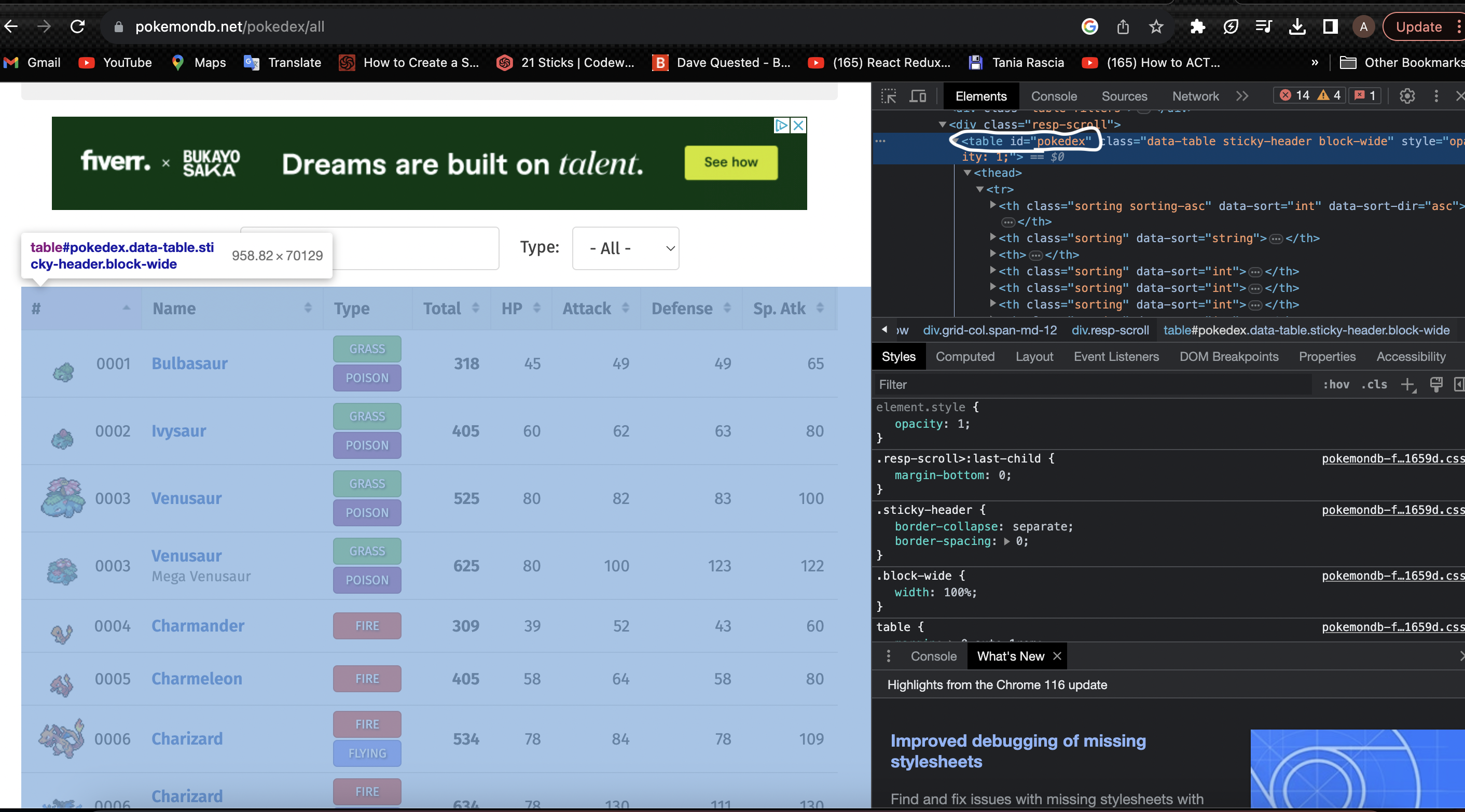
for this particular table we have an Id attribute which makes it easier to select the item. If you have a class it is also not a big deal, there maybe cases where they have the same class name in which case you will use the find_all method and select using indexing.
table = soup.find('table', {'id': 'pokedex'})
This line of code finds the table with the Id of pokedex which is the table we want in this case.
Now we keep inspecting back the elements of the table and we can find that all the heading of the table come under a th tag.So, we can select them with that.
titles = table.find_all('th')
If we print this we can see the output something like this
[<th class="sorting" data-sort="int"><div class="sortwrap">#</div></th>,
<th class="sorting" data-sort="string"><div class="sortwrap">Name</div></th>,
<th><div class="sortwrap">Type</div></th>,
<th class="sorting" data-sort="int"><div class="sortwrap">Total</div></th>,
<th class="sorting" data-sort="int"><div class="sortwrap">HP</div></th>,
<th class="sorting" data-sort="int"><div class="sortwrap">Attack</div></th>,
<th class="sorting" data-sort="int"><div class="sortwrap">Defense</div></th>,
<th class="sorting" data-sort="int"><div class="sortwrap">Sp. Atk</div></th>,
<th class="sorting" data-sort="int"><div class="sortwrap">Sp. Def</div></th>,
<th class="sorting" data-sort="int"><div class="sortwrap">Speed</div></th>]
This is a list and you can see all the column headings are in there so we can get them by looping over them and accessing the text property available to us.
table_titles = []
for title in titles:
table_titles.append(title.text.strip())
We loop over the list and push each item into the table_titles list. We are using the strip method to get rid of the newline character at the end.
Now if we print table_titles we can see something like this
['#',
'Name',
'Type',
'Total',
'HP',
'Attack',
'Defense',
'Sp. Atk',
'Sp. Def',
'Speed']
We get a list of our desired column names.
Next we need to create the DataFrame for that we need to import the pandas library.
import pandas as pd
df = pd.DataFrame(columns = table_titles)
This line of code will assign the column headings with items in the list table_titles.
Now is the tricky part we need to get the row datas. So, if you look closely using the inspect element in your chrome dev tools you can see that each row is depicted by a tr which is a table row and is inside that you can see a td which is the table data what we are actually looking for. Now we know we have to go two levels deep so let’s get started.
column_data = table.find_all('tr')
This will return all the table rows(as a list) inside that table we selected now we need loop over each one and get the table data.
for row in column_data[1:]:
row_data = row.find_all('td')
individual_row_data = [data.text.strip() for data in row_data]
length = len(df)
df.loc[length] = individual_row_data
let’s go over line by line the fist line states the start of a for loop and we are starting from the second element because the element appears to be a empty list which is of no use to us.
Now we find all the td elements inside the tr element.
We append items to the individual_row_data variable using list comprehension. The syntaxt goes like new_list = [expression for item in iterable if condition] so I first strip the text of blank spaces and then place it in the list.
Now it’s time to insert into the dataframe for that we are using df.loc method which is a primary method to select rows and columns using index-labeling. Here we are using 0,1,2.. so on as indexes. So, we can use the length of the df in each iteration as the index and insert the row data. for example in the first iteration it will be df.loc[1] = individual_row_data and for the second iteration it will df.loc[2] = individual_row_data and so on.
So after all the iterations are complete we will have a complete table ready for us if you need to export it as a csv file you can do it using
df.to_csv('your path',index= False)
you need to provide a path where you want the file to be placed and we are using the index false option because we don’t want an extra column showing the index values because we used it because we needed them in pandas you probably won’t need them in Excel or any other tools like that.